The online version of this article (https://doi.org/10.18148/srm/2026.v20i1.8479) contains supplementary material.
Respondents’ interest in a survey’s topic is used frequently by survey researchers to explain and predict survey errors. Whether respondents are interested in a survey’s topic relates to their participation and cognitive answering processes, which consequently impacts nonresponse and measurement errors. With respect to participation in surveys and nonresponse error, past research has argued that interest in the topic of a survey increases the likelihood of a potential respondent participating in the survey (e.g., Groves et al., 2006; Groves et al., 2004; Groves et al., 2000). For instance, Frankel and Hillygus (2014) found that politically interested respondents in political science panel surveys were less likely to attrit than respondents with lower political interest. Along these lines, in an experimental study, McGregor et al. (2022) showed that not informing respondents about a potentially uninteresting survey topic (in their case political content) yielded a higher response rate compared to mentioning the topic. Similarly, Groves et al. (2004) reported that respondents were more likely to participate if they perceived the survey topic as interesting.
Regarding the cognitive answering process and measurement error, the satisficing theory (Krosnick, 1991, 1999) suggests that respondents decide on how much effort they will put into answering survey questions based on their task-related abilities, question difficulty, and motivation. A frequently used operationalization of respondent motivation is a respondent’s interest in question or survey topics (Blazek & Siegel, 2024; Roberts et al., 2019; Sturgis & Brunton-Smith, 2023). For example, with respect to surveys that include many questions on political attitudes and electoral behavior, Roßmann et al. (2018) and Schmidt et al. (2019) found that politically interested respondents were less likely to engage in detrimental response behavior (e.g., straightlining) compared to politically less interested respondents. In a similar vein, Gummer and Roßmann (2015) showed that politically interested persons invested more time into answering cognitive demanding questions than less interested respondents.
When trying to better understand data quality with respect to the participation and answering processes, more knowledge about respondents’ topic interests is required. In addition, we argue that research could more actively use the content of questionnaires to enhance survey performance. The content of a survey is under the control of the researchers who design and conduct it. While the inclusion of most questions will surely be the result of the research questions that researchers want to answer, we assume that there will always be some leeway to include questionnaire content that can be used for motivational purposes. We find it reasonable to assume that researchers can possibly include questions that provide respondents with a more engaging survey experience, which could help to enhance their motivation and, thus, improve their answering quality and participation behavior in future surveys. Utilizing a strategy involving respondents’ topic preferences would necessarily involve several trade-off decisions such as reducing the number of questions of interest to researchers or extending the questionnaire for the purpose of including questions that target the interests of respondents. While including interesting questions may result in a longer survey, Montaquila et al. (2013) found that including additional engaging items yielded response rates comparable to those of a shorter, less engaging questionnaire. However, before future research can dive into the trade-offs between different errors, foundational research is required on measuring and understanding respondents’ topic preferences and how respondents differ in their interests.
In the present study, we aimed to enable researchers to measure and utilize respondents’ topic preferences. Consequently, our first goal was to develop and test a measurement instrument for topic preferences in surveys. Our second research goal was to assess topic preferences in a probability-based sample. We also aimed at replicating our findings in frequently used non-probability samples.
In the following, we introduce our research goal and respective research questions. We then detail our study design that includes three studies carried out using different types of samples, which are used frequently by social science research.
Measures exist for respondents’ survey experience or assessment (e.g., Huang et al., 2015; Kaczmirek et al., 2014) and self-reported answering behavior (e.g., Meade & Craig, 2012) that could provide insights into how engaging or interesting respondents perceived a survey and its topic. In addition, the NASA Task Load Index (NASA-TLX) is a generalist measure for a task’s workload (Hart, 2006; Hart & Staveland, 1988) that could be used in the survey case. However, we argue that a specialized measurement instrument for respondents’ topic preferences is needed to fulfil three practical requirements. First, it should cover various topics that a researcher can include in their questionnaires. Second, it should enable researchers to compare and rank how interesting different topics are to respondents. Third, it should ask respondents directly which topic they would prefer to answer questions about and not just ask about their general interest in topics. Thus, our first research goal was to develop and test such a measurement instrument.
When asking respondents about their interest in a topic or, more specifically, about their interest in answering questions on a topic, a question of validity arises: is the respondents’ understanding of a topic the same as the researchers’ understanding? If an instrument to measure topic preferences lacks validity, utilizing a questionnaire’s content for motivational purposes may fail in its purpose or even have unintended effects when researchers include questions that are not the content respondents find interesting with respect to answering questions. Previous research has shown that respondents often interpret questions differently than the researchers who designed them (Conrad & Schober, 2000; Schober & Conrad, 1997). This potential problem might be especially challenging in self-administered modes in which an interviewer is not present to clarify a question’s meaning. Consequently, to develop a valid measurement instrument for topic preferences, we aimed at answering the following research question (RQ):
Understanding which survey question covers which topic is an intellectual task. Previous research on knowledge questions in surveys has shown that respondents with higher education and topic interest were more likely to answer these questions correctly (Gummer & Kunz, 2022; Höhne et al., 2021). We acknowledge that these tasks differ from knowing which survey topic includes which questions. However, we assume that similar mechanisms are at play and that a task-related ability is positively associated with a respondent’s likelihood to correctly assess a question’s topic. Differences in validity between subgroups could potentially result in a biased measure of topic preferences. This bias could endanger the feasibility of utilizing content as a tool for designing more engaging surveys, especially when targeting population subgroups. Thus, we aimed at answering a second RQ:
Since we suspected that some respondents might struggle with correctly identifying a survey question’s topic, we investigated the use of illustrative examples to clarify the meaning of our topic preference instrument and narrow down the topic for respondents to improve its validity. We created two versions of the instrument. Whereas version A did not include any illustrative examples, version B used illustrative examples for each topic. We assumed that this approach could increase the validity of the scale, since it conveyed the researchers’ understanding of what a specific topic is to respondents. Regarding the use of illustrative examples, our third RQ was:
Given the relevance of survey content and a lack of knowledge about which topics are interesting for respondents to answer, our second research goal was to assess topic preferences in a probability-based sample. Since survey researchers require more knowledge about which topics respondents generally like (and do not like), we aimed at answering our fourth RQ:
Moreover, not all respondents share the same interests. Knowing the specific topic interests of population subgroups could be vital for tailoring survey content to specific groups, for instance, to enhance their participation rates. Such an approach would be in line with the Adaptive Survey Design paradigm (Schouten et al., 2017; Wagner, 2008). Consequently, our fifth RQ was aimed at assessing topic preferences among population subgroups:
To answer our five research questions, we conducted three empirical studies. Study 1 was devoted to developing and testing the measurement instrument (RQ1, RQ2, RQ3). For this study, we conducted a web-based experiment in a non-probability sample drawn from an online access panel.
In Study 2, we assessed topic preferences in a probability-based panel sample (RQ4, RQ5). For this purpose, we implemented the measurement instrument developed in Study 1 in the GESIS Panel.pop (“Population Sample”), a probability-based mixed-mode panel in Germany.
To complement both studies with a different sample, gather additional insights, and test the robustness of our findings, we conducted Study 3 based on a non-probability sample recruited via social network platforms, a pilot study of the GESIS Panel.dbd, which focuses on collecting digital behavioral data (dbd).
Our selection of samples enabled us to compare findings between different samples, all of which are frequently used in social science research: non-probability commercial online access panels, probability-based academic panels, and non-probability social network recruited samples. Utilizing the commercial online access panel in Study 1 was a cost-efficient way to develop and validate our measurement instrument and implement the different experimental conditions necessary for this validation.
Study 1 aimed at developing and validating a measurement instrument for respondent’s topic preferences (i.e., answering RQ1, RQ2, and RQ3).
We conducted a web survey with individuals sampled from a large German commercial online access panel that is frequently used by academic and commercial researchers (i.e., panelists answer surveys on various topics). We used quota sampling based on age, gender, and education in a survey fielded in November 2022. A total of 1621 respondents followed the survey invite of which 472 were screened out due to full quotas, 48 broke off (break-off rate: 4%), yielding a total of 1101 complete cases. We followed the AAPOR (2016) recommendations and defined break-off cases as those who completed less than 50% of the questionnaire. Additionally, we defined those who did not complete our survey experiment (see below) as break-off cases so to not impair our analyses.
The questionnaire contained questions on political attitudes and behavior as well as subjective well-being. On average, the questionnaire took 6 min and 41 s to complete (median = 5 min and 20 s). The questionnaire layout was responsive to facilitate answering on a mobile device with a small screen. In total, 49% of respondents answered on mobile devices.
In the last quarter of the questionnaire, we included the survey experiment in which we tested the different versions of our measurement instrument (see below). We randomly allocated respondents to two experimental groups: one group received version A of the measurement instrument that did not include illustrative examples, whereas the second group received version B of the instrument featuring illustrative examples that specified our understanding of the different topics (see Appendix A for English translations of the instrument). We used t‑ and χ2-tests to test whether the randomization worked as intended. We found no differences between the groups regarding age (two-sided t‑test: p = 0.71, ∆ = 0.35), gender (χ2 (df = 1) = 0.17, p = 0.68), or residence in Germany (χ2 (df = 2) = 0.70, p = 0.70). However, we did find a difference between the groups with respect to education (χ2 (df = 2) = 10.03, p = 0.01). The experimental group that did not receive an example had a higher share of respondents with high education compared to the experimental group that received an illustrative example. Based on this finding, we checked the programming of the survey but were unable to detect any technical error. Thus, we assumed that these differences occurred by chance and decided to control for education in our analyses (see below).
We developed our topic preference scale based on the content of the GESIS Panel.pop (for a more detailed description, see Study 2). This multi-topic, multi-purpose academic panel features content from various social science disciplines and adjacent fields. The content of the GESIS Panel.pop is created by external researchers who can field their questions in this infrastructure. Since the GESIS Panel.pop has been operational for more than a decade, we drew on their classification of question modules and content because it was reasonable to assume it includes the major fields and topics of the social sciences. Based on this classification, we conducted an expert review of all the content ever fielded in the GESIS Panel.pop and adjusted our list of topics to cover all the major topics asked. We used this list in developing our topic preference scale. We asked respondents: “How interesting do you find answering questions on the following topics?” (English translation by the authors). The topic preference scale included nine items that were derived from the classification of question modules and content by the GESIS Panel.pop: “Satisfaction and Well-Being,” “Personality and Values,” “Nature and Environment,” “Current Crises,” “Work and Leisure,” “Economy and Society,” “Political Attitudes and Participation,” “Social Networks and Media,” and “Flight and Migration.”
After we provided respondents with the topic preference scale, we showed them questions and asked them to judge to which of the topics they belonged. Respondents had the option to choose multiple topics for each question. We asked each respondent only to complete this task for three questions to avoid break-offs due to cognitive burden. We created three experimental groups, each containing three different questions to judge (1 “Economy and Society, Work and Leisure, Nature and Environment”; 2 “Social Networks and Media, Satisfaction and Well-Being, Personality and Values”; 3 “Political Attitudes and Participation, Flight and Migration, Current Crises”). We chose similar topics per experimental group to ensure that correct answers were not immediately obvious. To further avoid order effects, we randomized the response options. For English translations of the question texts, see Appendix A.
To answer our RQs, we created different dependent variables. Based on the three assessment test questions, we first computed for each question whether a respondent correctly answered the question (0 = no, 1 = yes). Then, we calculated the share of correct assessments for each respondent. In addition to analyzing the assessments on a question level (see below), we created a data set in long format that contains three assessments per respondent (i.e., assessments clustered in respondents). This data set includes 3303 data points.
To evaluate the comprehensibility of our measurement instrument, we used a one-item comprehensibility probe (Neuert et al., 2025). The respondents’ self-reported comprehensibility ranged from 1 (not at all comprehensible) to 7 (completely comprehensible). We rescaled the variable to range between 0 and 1.
To assess detrimental response behavior to the topic preference scale as a consequence of respondents trying to reduce their cognitive load, we computed a set of four indicators that prior research had used to assess how question design impacted answers (e.g., Gummer & Kunz, 2021).
In addition, we created several independent variables. To gauge the effect of the experimental treatment, we created a dummy variable indicating whether respondents received an illustrative example or not when answering the topic preference scale (0 = no example, 1 = example).
We operationalized the respondents’ task-related ability using three different variables. Based on the quota-question on education, we created a categorical variable (1 = low, 2 = intermediate, 3 = high). We further used topic preferences for the respective topic as metric variables that ranged from 1 (not interesting at all) to 7 (very interesting). Finally, based on the overall survey assessment at the end of our survey, we created a variable on how interesting respondents perceived the questionnaire in general. This variable ranged from 1 (not at all) to 5 (very much). We reasoned that the variable would capture the respondents’ overall engagement with the survey and their commitment to properly progress through all the steps of the cognitive response process.
For developing the measurement instrument, we investigated the topic preferences reported in the sample to assess the discriminatory properties of the scale. To identify differences between topics, we compared the distributions between all topic preference variables using χ2-tests. We also compared mean values between topics using t‑tests and ranked the means for illustration purposes. We calculated tests that compare topic preferences with one-another on a subsample containing only complete cases for the topic preference scale. Thus, respondents that skipped one or more items were excluded. In addition, we performed a principal component analysis (PCA) for the 9 topic preferences. We used varimax rotation.
Regarding RQ1 (“Do respondents correctly identify the topic of survey questions?”), we analyzed the share of respondents correctly identifying one, two, and three topics.
To answer RQ2 (“Which respondents are correctly identifying the topic of survey questions?”), we ran a mixed effects logistic regression model. In this model, assessment questions were clustered in respondents (i.e., three questions per respondent). We used correct assessment of a question as a dependent variable. As independent variables, we included the education, interest in the topic of the respective question, and perceived interestingness of the survey. Following the satisficing theory (Krosnick, 1991, 1999), we included these variables to cover task-related ability and motivation, which determine a respondent’s likelihood to progress through all steps of the cognitive response process. Further, we included the experimental group as a control variable. Following prior research on knowledge questions (Gummer & Kunz, 2022; Höhne et al., 2021), we included socio-demographic control variables: gender (1 = male, 2 = female), age (1 = 18–30 years, 2 = 31–48 years, 3 = 49–63, 4 = older than 63), and region of residency (1 = West, 2 = East Germany).
To facilitate the interpretation of the logistic model, we calculated predicted probabilities for each independent variable, with all other variables held constant. We presented the predicted probabilities in plots. Since we were not interested in the effects of the control variables, we do not show them. Appendix Table B1 provides the full regression models including all parameters.
Concerning RQ3 (“Does the use of illustrative examples for topics help respondents to correctly identify a survey question’s topic?”), we further analyzed whether respondents were able to correctly match survey questions to topics. For this purpose, we investigated the number of questions a respondent correctly matched with topics. We compared the share of correct assessments between the experimental groups using t‑tests for difference. To account for the different distributions of educational levels between the experimental groups, we additionally estimated a mixed effects logistic regression model using the correct matches as a dependent variable, and the experimental group and educational level as independent variables (see Appendix Table B1 for the full model). Finally, we utilized t‑tests to assess whether respondents’ self-reported comprehensibility scores differed when they were or were not provided with illustrative examples.
In addition, to assess whether respondent’s topic preferences were affected by the offer of illustrative examples, we compared mean preferences between the experimental groups using t‑tests for difference. To assess how answering quality and response behavior was impacted by providing illustrative examples, we compared our indicators for extreme responding, acquiescence, midpoint responding, and item nonresponse between the experimental groups using tests for differences in proportions. We also calculated Ordinary Least Squares (OLS) regression models using the different data quality indicators as dependent variables and the experimental group and educational level as independent variables (see Appendix Table B2 for the full models).
Table 1 shows descriptive statistics of the respondents’ topic preferences. For 33 out of 36 comparisons of mean preferences, we found differences (paired t‑tests, all p < 0.05). Based on χ2-tests, we also found that the response distributions of the 9 items differed 36 out of 36 times (all p < 0.05). We interpret this result as the first evidence for the discriminatory power of the instrument.
Table 1 Respondents’ Topic Preferences in Study 1.
Variable | Mean | Std. Dev. | Min | Median | Max |
N = 1060 | |||||
Satisfaction and Well-Being | 5.30 | 1.41 | 1 | 5 | 7 |
Personality and Values | 5.23 | 1.49 | 1 | 5 | 7 |
Nature and Environment | 5.05 | 1.61 | 1 | 5 | 7 |
Current Crises | 4.96 | 1.66 | 1 | 5 | 7 |
Work and Leisure | 4.88 | 1.54 | 1 | 5 | 7 |
Economy and Society | 4.71 | 1.57 | 1 | 5 | 7 |
Political Attitudes and Participation | 4.44 | 1.81 | 1 | 4 | 7 |
Social Networks and Media | 4.44 | 1.69 | 1 | 4 | 7 |
Flight and Migration | 4.30 | 1.82 | 1 | 4 | 7 |
Table 2 details the factor loadings of the topic preference scale. According to the Kaiser criterion, we found that the nine items load on two underlying dimensions. The first component represents a latent dimension that captures public, political topics, whereas the second component represents a latent dimension that captures private, personal topics. Again, we interpret these findings as the first evidence that the instrument discriminates between topics, but also as an indication that there are topics that are related.
Table 2 Varimax-Rotated Principal Component Analysis of Topic Preferences in Study 1.
Variable | Loadings 1 | Loadings 2 | Uniqueness |
N = 1060 | |||
Nature and Environment | 0.70 | 0.26 | 0.44 |
Current Crises | 0.33 | 0.76 | 0.31 |
Personality and Values | 0.84 | 0.21 | 0.25 |
Economy and Society | 0.33 | 0.76 | 0.31 |
Satisfaction and Well-Being | 0.86 | 0.20 | 0.23 |
Flight and Migration | 0.18 | 0.80 | 0.33 |
Work and Occupation | 0.60 | 0.41 | 0.47 |
Political Attitudes and Participation | 0.23 | 0.77 | 0.35 |
Social Networks and Media | 0.51 | 0.32 | 0.64 |
Eigenvalues | 4.60 | 1.07 | |
We found that 7% of the respondents did not correctly identify any survey question’s topic. In contrast, 22% of the respondents correctly identified one, 15% correctly identified two, and 56% correctly identified three. These findings highlight that the majority of respondents shared the same understanding as researchers when asked about survey topics. Unfortunately, our data also showcases that a non-negligible share of respondents did not share the same understanding as researchers. We interpret these results as supporting the notion that researchers can ask their survey respondents about topic preferences, but that respondents could be supported in reporting better answers when provided with more appropriate examples or other stimuli.
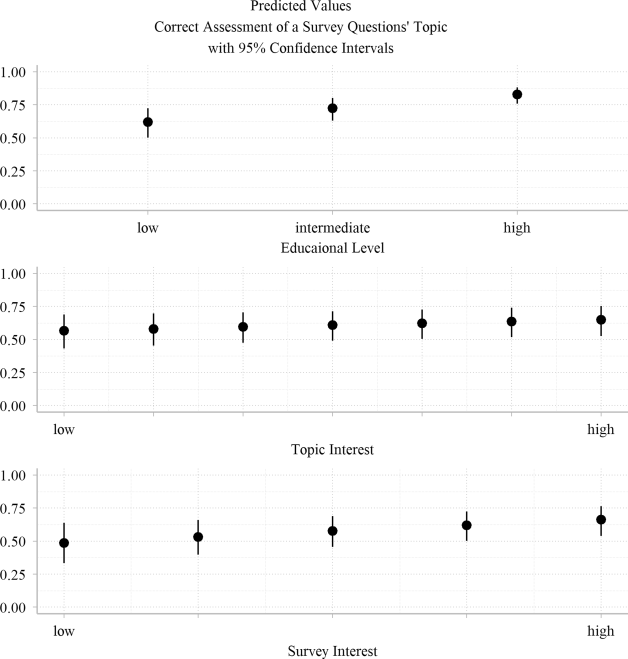
Fig. 1 shows the predicted values of the correct assessment of a survey question’s topic by different variables measuring task-related ability. Higher education and general interest in the survey had a positive impact on the correct assessment of a survey questions’ topic, whereas the respective topic interest had no effect. Respondents with higher education (p = 0.00, ∆ = 0.16) and high interest in the survey (p = 0.03, ∆ = 0.11) were more likely to correctly link a survey question to its respective topic than respondents with lower education and lower survey interest.
Concerning the usefulness of illustrative examples for correctly linking specific survey questions to topics, providing examples seems to have a limited impact on the correct assessment of survey questions. While we found that respondents who received an illustrative example were marginally less likely to correctly link survey questions with the respective topic than respondents who did not receive an example (p < 0.01, ∆ = 0.06), this effect disappeared when controlling for respondents’ education in an additional regression model (p = 0.168, ∆ = −0.03).
Receiving an illustrative example for topics had no impact on respondents’ assessment of their degree of preference for eight out of nine topics (all eight: p > 0.05). The example only had an impact on substantive responses to the item when providing an example for “Political Attitudes and Participation”: respondents who received an illustrative example rated the topic “Political Attitudes and Participation” less interesting than respondents who did not receive an example (p < 0.01, ∆ = 0.31).
The share of acquiescence (proportion test: p = 0.68, ∆ = 0.01; regression: p = 0.85, ∆ = −0.00), extreme responding (proportion test: p = 0.38, ∆ = −0.03; regression: p = 0.29, ∆ = 0.02), midpoint responding (proportion test: p = 1.00, ∆ = 0.00; regression: p = 0.80, ∆ = 0.00) and item non-response (proportion test: p = 0.69, ∆ = −0.00; regression: p = 0.24, ∆ = 0.00) did not differ between the two experimental groups.
Regarding question comprehensibility, we found that an illustrative example had no effect on respondents. Respondents’ mean comprehensibility score did not differ between the experimental groups (t-test: p = 0.86, ∆ = 0.00). Controlling for respondents’ education in an additional regression analysis yielded similar results (p = 0.88, ∆ = 0.00).
Study 2 aimed at assessing respondents’ topic preferences in a probability-based sample (i.e., answering RQ4 and RQ 5). For this purpose, we fielded the measurement instrument validated in Study 1.
In Study 2, we relied on data from the probability-based GESIS Panel.pop “Population Sample” (Bosnjak et al., 2018). The GESIS Panel.pop is an open academic panel in Germany. After recruitment in 2013, the panel went fully operational in 2014. Before switching the frequency to four waves per year in 2021, six waves per year were conducted by the GESIS Panel.pop. With each invitation, respondents receive an unconditional 5€ incentive.
The GESIS Panel.pop is designed as a self-administered mixed mode survey in which respondents are free to choose a (paper-based) mail or web mode for participation. Each wave’s questionnaire takes approximately 20 to 25 min to complete and contains varying content modules from different social science disciplines. Researchers submit these modules to be fielded in the GESIS Panel.pop.
For recruitment in 2013, a sample was drawn from German municipalities’ population registers and interviewed in a face-to-face mode. This short recruitment interview achieved an AAPOR Response Rate 1 (AAPOR RR1; AAPOR, 2016) of 36%. A total of 4777 respondents were successfully recruited as panelists. Refreshment samples were recruited as part of the German General Social Survey (GESIS, 2018, 2019) in 2016 and 2018 as well as the International Social Survey Programme (ISSP Research Group, 2024) in 2021, which also relied on samples drawn from German municipalities’ population registers. These surveys achieved AAPOR RR1s of 33% (2016), 31% (2018), and 37% (2021). All in all, 1710 (2016), 1607 (2018), and 764 (2021) respondents were successfully recruited for the GESIS Panel.pop (Schaurer et al., 2020; Schaurer & Weyandt, 2018; Stadtmüller et al., 2023).
We implemented the topic preference scale validated in Study 1 in wave “ka” (first wave in 2023). This wave was fielded between February 22 and April 18, 2023. A total of 4998 panelists were invited, of which 4564 completed the survey, yielding a completion rate of 91%. For our analyses, we used release version 54.0.0 of the GESIS Panel.pop (2024) that included wave “ka” data.
Based on Study 1, we decided to implement the topic preference scale without illustrative examples. After an expert review and consultation from the GESIS Panel research staff, we decided to split the item “Work and Leisure” into two separate items that we assumed could yield more granular insights. In addition, we slightly adjusted the wording of a few items to provide more detail for respondents (see Appendix A for the question wording in Study 2).
For a dependent variable in our analyses, we used the respondents’ topic preferences. Based on our measurement instrument, we created one variable per survey topic (a total of 10 variables) by which we measured how interesting respondents perceived the respective topic (1 = not at all interesting, 7 = very interesting).
For independent variables, we used standard socio-demographic characteristics: respondents’ gender (1 = male, 2 = female), education (1 = low, 2 = intermediate, 3 = high), age (1 = younger than 49, 2 = 49–63, 3 = older than 63), and region of residency (1 = West, 2 = East Germany). We also used substantive variables describing the political and societal (dis-)engagement of respondents to grasp differences between groups. Thus, we relied on respondents’ general social trust (1 = you can never be too careful, 7 = most people can be trusted) and political interest (1 = not at all, 5 = very strong). We standardized both variables to enable a comparison of the regression coefficients.
Regarding RQ4 (“Which questionnaire topics do survey respondents prefer to answer?”), we investigated the topic preferences in our sample. To identify differences between topics, we compared the distributions between all topic preference variables using χ2-tests. We also compared mean values between topics using t‑tests, and ranked these for illustration purposes.
To learn more about the relationship between different topics and investigate whether they measured latent constructs, we performed a PCA for the 10 topic preferences. We used varimax rotation.
Concerning RQ5 (“How do respondents differ in their topic preferences?”), we compared topic preferences across subgroups of respondents based on socio-demographic and substantive covariates. To gauge these effects, we fitted OLS regressions with robust standard errors using topic preferences as dependent variables and the selected covariates as independent variables. We computed one model per topic. To facilitate comparison between models, we plotted estimated effects for all the effects that were significant with p < 0.05. Full regressions models are available in Tables B3–B5 in the Appendix.
Table 3 shows descriptive statistics of respondents’ topic preferences. “Nature and Environment” was the most popular topic, whereas “Social Networks and Media” was the least popular topic in our sample. Nevertheless, the average interest in all topics was positive. For 44 out of 45 tests for differences in means, we found statistically significant differences with p < 0.05. Using χ2-tests, we also found the response distributions of the 10 items to differ 45 times out of 45 (all p < 0.05).
Table 3 Respondents’ Topic Preferences in Study 2.
Variable | Mean | Std. Dev. | Min | Median | Max |
N = 4336 | |||||
Nature and Environment | 5.43 | 1.34 | 1 | 6 | 7 |
Current Crises | 5.32 | 1.42 | 1 | 6 | 7 |
Personality and Values | 5.26 | 1.36 | 1 | 5 | 7 |
Economy and Society | 5.08 | 1.36 | 1 | 5 | 7 |
Leisure and Rest | 4.96 | 1.34 | 1 | 5 | 7 |
Satisfaction and Well-Being | 4.85 | 1.51 | 1 | 5 | 7 |
Flight and Migration | 4.83 | 1.58 | 1 | 5 | 7 |
Work and Occupation | 4.70 | 1.62 | 1 | 5 | 7 |
Political Attitudes and Participation | 4.52 | 1.61 | 1 | 5 | 7 |
Social Networks and Media | 4.42 | 1.51 | 1 | 4 | 7 |
Table 4 shows the results of our PCA. As in Study 1, according to the Kaiser criterion, topic preferences have two components. The first component represents a latent dimension that captures public, political topics, whereas the second component represents a latent dimension that captures private, personal topics.
Table 4 Varimax-Rotated Principal Component Analysis of Topic Preferences in Study 2.
Variable | Loadings 1 | Loadings 2 | Uniqueness |
N = 4336 | |||
Nature and Environment | 0.41 | 0.54 | 0.53 |
Current Crises | 0.81 | 0.19 | 0.31 |
Personality and Values | 0.24 | 0.77 | 0.35 |
Economy and Society | 0.81 | 0.22 | 0.30 |
Leisure and Rest | 0.04 | 0.73 | 0.46 |
Satisfaction and Well-Being | 0.08 | 0.78 | 0.39 |
Flight and Migration | 0.83 | 0.14 | 0.30 |
Work and Occupation | 0.16 | 0.59 | 0.62 |
Political Attitudes and Participation | 0.77 | 0.16 | 0.39 |
Social Networks and Media | 0.29 | 0.60 | 0.56 |
Eigenvalues | 4.24 | 1.56 | |
Figs. 2 and 3 show the effects of respondents’ characteristics on their topic interests. These effects can be interpreted with respect to how specific groups of respondents differ in their interest in the respective topics. A negative effect indicates that respondents of a group are less interested in a topic compared to the reference group, whereas a positive effect indicates higher interest. We found that women were more interested in six out of six personal topics, and more interested in one out of four political topics than men. However, they were less interested in the topic “Economy and Society” than men. Higher educated respondents were less interested in two out of six personal topics and more interested in one out of four political topics than lower educated respondents. With increasing age, respondents were significantly less interested in five out of six personal topics. Additionally, older respondents were significantly more interested in the topic “Nature and Environment” as well as four out of four political topics. Respondents who reside in East Germany were significantly more interested in two out of six personal topics and significantly less interested in one out of four political topics than respondents living in West Germany. Social trusting respondents were more interested in six out of six personal topics and four out of four political topics. Political interested respondents were more interested in four out of six personal topics and four out of four political topics than respondents with low political interest. However, political interest had a negative impact on the interest in the topic “Leisure and Rest.”
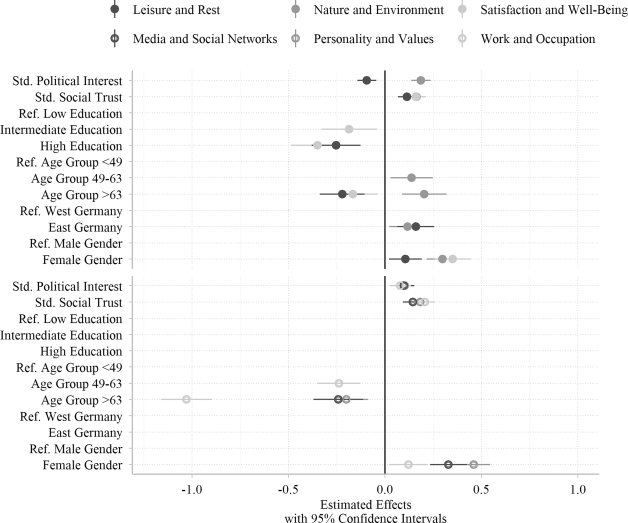
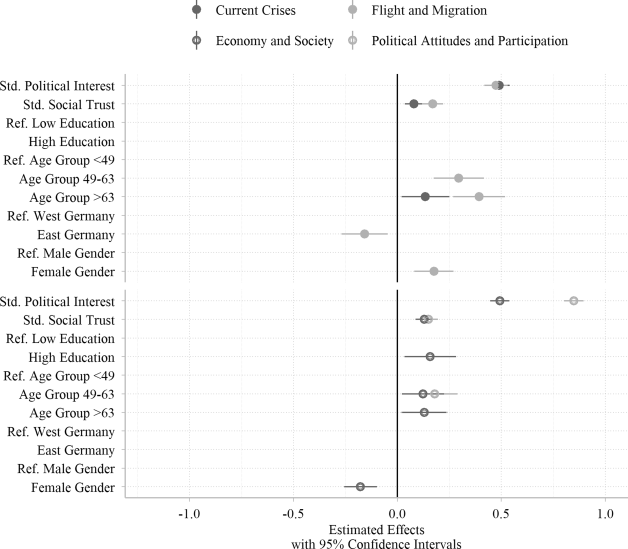
Comparing effect sizes, political interest was most important for interest in political topics. In contrast, social trust and socio-demographical variables were equally or more important than political interest for an interest in personal topics. The socio-demographical and political variables explained between 2% and 9% of the variance of interest in personal topics and between 13% and 32% of the variance of interest in political topics. Therefore, we were better able to account for differing interests in political topics by using our selected variables than for interests in personal topics.
To complement and replicate the findings on respondents’ topic preferences in Study 1 and Study 2, we fielded the measurement instrument in Study 3 as a non-probability sample recruited via social network sites.
For Study 3, we utilized data from a pilot study of the GESIS Panel.dbd (Digital Behavioral Data Sample). The main objective of this pilot study was to test the recruitment of participants for a web tracking study (Clemm von Hohenberg et al., 2024), but it included a web-based survey. In this survey, we fielded our measurement instrument on respondents’ topic preferences. For the pilot study of the GESIS Panel.dbd, a non-probability sample was recruited using ad-based sampling on Meta Inc. platforms (Facebook and Instagram) (for a general description of this approach, see Pötzschke et al., 2023).
The initial sample was recruited between May 18 and July 1, 2023. A total of 45,892 respondents clicked on an ad, either on Facebook or Instagram. Of those 45,892 respondents, 2667 completed the initial welcome survey (completion rate: 6%), and 988 respondents consented to becoming part of the panel. Respondents received a 5€ incentive for registering for the GESIS Panel.dbd.
We invited these 988 respondents to the web survey, of which 862 respondents completed the survey, yielding a completion rate of 87%. Again, each respondent received a conditional incentive of 5€. This survey was fielded between July 5 and August 9, 2023. On average, the questionnaire took 5 min and 11 s (median = 3 min and 53 s) to complete. In the survey, we implemented the adapted topic preference scale also used in Study 2 (see Appendix A for the question wording).
As a dependent variable in our analyses, we used respondents’ topic preferences. Based on our measurement instrument, we created one variable per survey topic (a total of 10 variables) by which we measured how interesting respondents perceived the respective topic. These variables had values between 1 (not at all interesting) and 7 (very interesting).
To identify differences in topic preferences, we compared the distributions between all topic preference variables using χ2-tests. We also compared mean values between topics using t‑tests and ranked these for illustrative purposes.
As before, we investigated the relationship between different topics and underlying latent constructs by performing a PCA for the 10 topic preferences. Again, we used varimax rotation.
Table 5 shows descriptive statistics of respondents’ topic preferences in the pilot study of the GESIS Panel.dbd. For 36 out of 45 tests for differences in means, we found statistically significant differences (all p < 0.05). Using χ2-tests, we also found the response distributions of the 10 items to differ 45 out of 45 times (all p < 0.05). In contrast to the probability sample (Study 2), “Personality and Values” was the most popular topic, whereas “Work and Occupation” was the least popular topic in our sample. As in the non-probability sample (Study 1), the topic “Nature and Environment” was one of the more interesting topics, whereas “Social Networks and Media” was among the least preferred ones. Average topic preferences differed between the samples, which may be important for survey practitioners who are seeking to increase the interestingness of their surveys. The ranking of topics seems to depend on the survey’s target population and its net sample.
Table 5 Respondents’ Topic Preferences in Study 3.
Variable | Mean | Std. Dev. | Min | Median | Max |
N = 843 | |||||
Personality and Values | 5.84 | 1.26 | 1 | 6 | 7 |
Political Attitudes and Participation | 5.84 | 1.43 | 1 | 6 | 7 |
Nature and Environment | 5.81 | 1.40 | 1 | 6 | 7 |
Current Crises | 5.62 | 1.45 | 1 | 6 | 7 |
Satisfaction and Well-Being | 5.61 | 1.38 | 1 | 6 | 7 |
Economy and Society | 5.60 | 1.32 | 1 | 6 | 7 |
Flight and Migration | 5.34 | 1.56 | 1 | 6 | 7 |
Leisure and Rest | 5.27 | 1.50 | 1 | 5 | 7 |
Social Networks and Media | 5.18 | 1.48 | 1 | 5 | 7 |
Work and Occupation | 5.11 | 1.60 | 1 | 5 | 7 |
The results of the PCA on the GESIS panel.dbd data are displayed in Table 6. As in studies 1 and 2, there are two components according to the Kaiser criterion: the first component represents a latent dimension that captures public, political topics, whereas the second component represents a latent dimension that captures private, personal topics. Since these results are comparable with the results of studies 1 and 2, we are confident that our findings are robust.
Table 6 Varimax-Rotated Principal Component Analysis of Topic Preferences in Study 3.
Variable | Loadings 1 | Loadings 2 | Uniqueness |
N = 843 | |||
Nature and Environment | 0.35 | 0.51 | 0.62 |
Current Crises | 0.75 | 0.17 | 0.42 |
Personality and Values | 0.28 | 0.68 | 0.46 |
Economy and Society | 0.75 | 0.20 | 0.40 |
Leisure and Rest | −0.03 | 0.74 | 0.46 |
Satisfaction and Well-Being | 0.08 | 0.78 | 0.39 |
Flight and Migration | 0.79 | 0.15 | 0.36 |
Work and Occupation | 0.24 | 0.53 | 0.66 |
Political Attitudes and Participation | 0.82 | 0.11 | 0.32 |
Social Networks and Media | 0.15 | 0.66 | 0.55 |
Eigenvalues | 3.79 | 1.57 | |
With our three studies, we set out to investigate which topics and content of a survey respondents like to answer questions about. The main purpose of Study 1 was to develop and test the instrument based on a non-probability online access panel sample. In Study 2, we implemented the instrument in a probability-based panel survey of the German population to measure topic preferences. Finally, we conducted Study 3 in a non-probability sample, recruited via social network platforms, for replication and generalization purposes.
Regarding our goal of developing a measurement instrument to capture respondents’ topic preferences (RQ1, RQ2, RQ3), we found that the majority of respondents correctly matched questions to the respective topics. However, there is room for further improvement of our measurement instrument as our subgroup analyses showed, and since a non-negligible share of respondents incorrectly classified survey topics. In general, we found that the use of illustrative examples did not help to improve the rate of correctly matched questions or the comprehensibility of the instrument.
Regarding our research question on the topic preferences of survey respondents (RQ4), in three independent studies, we found variation between respondents on which topics they would prefer to answer. Analyzing the factor structure of the 10 topics (9 in Study 1) revealed two underlying latent dimensions: political and personal topics. These findings were consistent across all three studies in which we fielded the instrument. The ranking of topics varied across the studies—which specific topics were most favored by respondents in each sample and which less so.
In Study 2, we found that topic preferences varied across the subgroups of respondents (RQ5). For example, “Political attitudes and Participation” was ranked least preferred among respondents with low political interest (mean = 2.11), whereas respondents with high political interest ranked this topic as most preferred (mean = 6.21). These findings highlight that topic preferences are not uniform for a whole population but vary across different subgroups. If topic preferences are utilized to improve participation and answering behavior, researchers need to consider this finding.
Our findings have implications for survey research. First, the variation we found in topic preferences within samples means that topics can be utilized to cater to respondents’ interests so to improve survey participation and response quality. Especially in the context of response quality, previous research has highlighted the impact that topic interest has on properly progressing through the cognitive process of answering questions (Krosnick, 1991, 1999). For two of our samples (most importantly, our probability-based sample), political topics were the least favored to answer by the average respondent. This result is troublesome news for political science surveys that feature major parts of the questionnaire on these topics. Based on our findings, we recommend researchers supplement their surveys with question modules that the average respondent is interested in answering such as “Subjective Well-being,” “Personality and Values,” or “Nature and Environment.”
Second, our finding on varying topic preferences across subgroups means that topic preferences can be used to tailor survey content to appeal to specific subgroups. This finding could be leveraged to improve participation rates and answering quality among respondents likely to not participate or who provide answers of low quality. A possible implementation of such a strategy would be to identify groups at risk of nonresponse or low answering quality and to offer them questionnaires in which parts of the questions are switched to a module they are likely to find interesting. Such an approach would, however, require more research on framing effects. It also would include a trade-off between collecting answers to the full content of a questionnaire and sacrificing parts of the questionnaire content to improve answering quality among selected cases. In this regard, previous research on the use of split-questionnaire design might offer valuable insights (e.g., Andreadis & Kartsounidou, 2020; Peytchev & Peytcheva, 2017; Raghunathan & Grizzle, 1995).
As always, the limitations of our study pose opportunities for future research. First, we relied on three samples that were recruited in different ways: Study 1 used a non-probability sample drawn from a commercial online access panel, Study 2 used the probability-based sample of the GESIS Panel.pop, and Study 3 used a non-probability sample from the GESIS Panel.dbd. All these samples have a common characteristic—they stem from panels. That is, the respondents in these samples have answered surveys before, what likely made the samples selective and resulted in participants who have prior experiences with survey contents. Specifically, topic preferences might be connected to questions asked in previous surveys. Especially with respect to RQ4, we believe that a replication of our study with a cross-sectional probability-based survey is necessary to test the generalizability of our results for the general population. Similarly, before generalizing our findings to surveys that utilize different samples, contents, or designs, we would recommend including our measurement instrument to assess topic preferences in these surveys and test whether our findings hold true. Having said that, across the different samples, we found highly consistent patterns in our PCAs with respect to which topical dimensions the average respondents prefer. Consequently, while we acknowledge the need for further studies, we are confident that our results will generalize.
Second, we drew on data from German studies. Context will vary between countries and, thus, topic preferences will likely differ from what we reported in the present study. We therefore encourage replication of our study in different countries or even in a cross-national survey to gain more insights. The measurement instrument we developed could be used for this purpose.
Third, we expect topic preferences to change over time as new and different societal discussions arise and values in the general population change. Our findings for Germany need to be taken as a snapshot, and we strongly advocate for subsequent replication to keep the knowledge up to date on which topics and content respondents like to answer questions about. For comparability, we recommend the use of samples and data collection protocols similar to those we used to field our measurement instrument.
Fourth, we conducted multiple studies to test our findings on the topic preferences of survey respondents. While offering a wide perspective on this topic, we were not able to dive into the particularities of the measurement instrument. We found no effect of using illustrative examples, yet still around 7% of respondents failed to correctly identify the topic of at least one out of three questions. This finding highlights that the measurement instrument can be further improved. Therefore, we invite future research on how to help respondents to better answer the instrument. Ultimately, such research would help bridge the potential gap in the understanding of survey topics between researchers and respondents.
AAPOR (2016). Standard definitions: final dispositions of case codes and outcome rates for surveys a, b, c
Andreadis, I., & Kartsounidou, E. (2020). The impact of splitting a long Online questionnaire on data quality. Survey Research Methods, 14(1), 31–42. https://doi.org/10.18148/SRM/2020.V14I1.7294. →
Blazek, D. R., & Siegel, J. T. (2024). Preventing satisficing: a narrative review. International Journal of Social Research Methodology, 27(6), 635–648. https://doi.org/10.1080/13645579.2023.2239086. →
Bosnjak, M., Dannwolf, T., Enderle, T., Schaurer, I., Struminskaya, B., Tanner, A., & Weyandt, K. W. (2018). Establishing an open probability-based mixed-mode panel of the general population in Germany. Social Science Computer Review, 36(1), 103–115. https://doi.org/10.1177/0894439317697949. →
Clemm von Hohenberg, B., Stier, S., Cardenal, A. S., Guess, A. M., Menchen-Trevino, E., & Wojcieszak, M. (2024). Analysis of web browsing data: a guide. Social Science Computer Review. https://doi.org/10.1177/08944393241227868. →
Conrad, F. G., & Schober, M. F. (2000). Clarifying question meaning in a household telephone survey. Public Opinion Quarterly, 64(1), 1–28. https://doi.org/10.1086/316757. →
Frankel, L. L., & Hillygus, D. S. (2014). Looking beyond demographics: panel attrition in the ANES and GSS. Political Analysis, 22(3), 336–353. https://doi.org/10.1093/pan/mpt020. →
GESIS (2018). German General Social Survey—ALLBUS 2016. https://doi.org/10.4232/1.12837. →
GESIS (2019). German General Social Survey—ALLBUS 2018. https://doi.org/10.4232/1.13325. →
GESIS (2024). GESIS Panel—Standard Edition. https://doi.org/10.4232/1.14386. →
Groves, R. M., Singer, E., & Corning, A. (2000). Leverage-saliency theory of survey participation: description and an illustration. Public Opinion Quarterly, 64(3), 299–308. https://doi.org/10.1086/317990. →
Groves, R. M., Presser, S., & Dipko, S. (2004). The role of topic interest in survey participation decisions. Public Opinion Quarterly, 68(1), 2–31. https://doi.org/10.1093/poq/nfh002. a, b
Groves, R. M., Couper, M. P., Presser, S., Singer, E., Tourangeau, R., Acosta, G. P., & Nelson, L. (2006). Experiments in producing nonresponse bias. Public Opinion Quarterly, 70(5), 720–736. https://doi.org/10.1093/poq/nfl036. →
Gummer, T., & Kunz, T. (2021). Using only numeric labels instead of verbal labels: stripping rating scales to their bare minimum in web surveys. Social Science Computer Review, 39(5), 1003–1029. https://doi.org/10.1177/0894439320951765. →
Gummer, T., & Kunz, T. (2022). Relying on external information sources when answering knowledge questions in web surveys. Sociological Methods & Research, 51(2), 816–836. https://doi.org/10.1177/0049124119882470. a, b
Gummer, T., & Roßmann, J. (2015). Explaining interview duration in web surveys. Social Science Computer Review, 33(2), 217–234. https://doi.org/10.1177/0894439314533479. →
Hart, S. G. (2006). Nasa-task load index (NASA-TLX); 20 years later. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 50(9), 904–908. https://doi.org/10.1177/154193120605000909. →
Hart, S. G., & Staveland, L. E. (1988). Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. In P. A. Hancock & N. Meshkati (Eds.), Advances in Psychology (pp. 139–183). North-Holland. https://doi.org/10.1016/S0166-4115(08)62386-9. →
Höhne, J. K., Cornesse, C., Schlosser, S., Couper, M. P., & Blom, A. G. (2021). Looking up answers to political knowledge questions in web surveys. Public Opinion Quarterly, 84(4), 986–999. https://doi.org/10.1093/poq/nfaa049. a, b
Huang, J. L., Bowling, N. A., Liu, M., & Li, Y. (2015). Detecting insufficient effort responding with an infrequency scale: evaluating validity and participant reactions. Journal of Business and Psychology, 30(2), 299–311. https://doi.org/10.1007/s10869-014-9357-6. →
ISSP Research Group. (2024). ZA8000 International Social Survey Programme: Health and Health Care II—ISSP 2021. https://doi.org/10.4232/5.ZA8000.1.0.0 →
Kaczmirek, L., Bandilla, W., Schaurer, I., & Struminskaya, B. (2014). GESIS Online Panel Pilot: einführende Mehrthemen-Welle (Umfrage 1): ZA5582 Datenfile Version 1.0.0. https://doi.org/10.4232/1.11570. →
Krosnick, J. A. (1991). Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied Cognitive Psychology, 5(3), 213–236. https://doi.org/10.1002/acp.2350050305. a, b, c
Krosnick, J. A. (1999). Survey research. Annual Review of Psychology, 50, 537–567. https://doi.org/10.1146/annurev.psych.50.1.537. a, b, c
McGregor, M., Pruysers, S., Goodman, N., & Spicer, Z. (2022). Survey recruitment messages and reported turnout—an experimental study. Journal of Elections, Public Opinion and Parties, 32(2), 322–338. https://doi.org/10.1080/17457289.2020.1730380. →
Meade, A. W., & Craig, S. B. (2012). Identifying careless responses in survey data. Psychological Methods, 17(3), 437–455. https://doi.org/10.1037/a0028085. →
Montaquila, J. M., Brick, J. M., Williams, D., Kim, K., & Han, D. (2013). A study of two-phase mail survey data collection methods. Journal of Survey Statistics and Methodology, 1(1), 66–87. https://doi.org/10.1093/jssam/smt004. →
Neuert, C. E., Kunz, T., & Gummer, T. (2025). An empirical evaluation of probing questions investigating question comprehensibility in web surveys. International Journal of Social Research Methodology, 28(3), 367–378. https://doi.org/10.1080/13645579.2024.2391957. →
Peytchev, A., & Peytcheva, E. (2017). Reduction of measurement error due to survey length: evaluation of the split questionnaire design approach. Survey Research Methods, 11(4), 361–368. https://doi.org/10.18148/srm/2017.v11i4.7145. →
Pötzschke, S., Weiß, B., Daikeler, J., Silber, H., & Beuthner, C. (2023). A guideline on how to recruit respondents for online surveys using Facebook and Instagram: Using hard-to-reach health workers as an example (GESIS Survey Guidelines). https://doi.org/10.15465/gesis-sg_en_045. →
Raghunathan, T. E., & Grizzle, J. E. (1995). A split questionnaire survey design. Journal of the American Statistical Association, 90(429), 54–63. https://doi.org/10.1080/01621459.1995.10476488. →
Roberts, C., Gilbert, E., Allum, N., & Eisner, L. (2019). Research synthesis. Public Opinion Quarterly, 83(3), 598–626. https://doi.org/10.1093/poq/nfz035. →
Roßmann, J., Gummer, T., & Silber, H. (2018). Mitigating satisficing in cognitively demanding grid questions: evidence from two web-based experiments. Journal of Survey Statistics and Methodology, 6(3), 376–400. https://doi.org/10.1093/jssam/smx020. →
Schaurer, I., & Weyandt, K. W. (2018). GESIS Panel Technical Report: Recruitment 2016 (Wave d11 and d12). GESIS. https://access.gesis.org/dbk/63525 →
Schaurer, I., Minderop, I., Bretschi, D., & Weyandt, K. W. (2020). GESIS Panel Technical Report: Recruitment 2018 (f11 and f12) Related to ZA5664 and ZA5665. GESIS. https://access.gesis.org/dbk/68673 →
Schmidt, K., Gummer, T., & Roßmann, J. (2019). Effects of respondent and survey characteristics on the response quality of an open-ended attitude question in web surveys. methods, data, analyses. https://doi.org/10.12758/MDA.2019.05. →
Schober, M. F., & Conrad, F. G. (1997). Does conversational interviewing reduce survey measurement error? Public Opinion Quarterly, 61(4), 576. https://doi.org/10.1086/297818. →
Schouten, B., Peytchev, A., & Wagner, J. (2017). Adaptive survey design (1st edn.). Chapman and Hall CRC. https://doi.org/10.1201/9781315153964. →
Stadtmüller, S., Minderop, I., & Weyandt, K. W. (2023). GESIS Panel Technical Report: Recruitment 2021 (i11 and i12) Related to ZA5664 and ZA5665. GESIS. https://access.gesis.org/dbk/76810 →
Sturgis, P., & Brunton-Smith, I. (2023). Personality and survey satisficing. Public Opinion Quarterly, 87(3), 689–718. https://doi.org/10.1093/poq/nfad036. →
Wagner, J. (2008). Adaptive survey design to reduce nonresponse bias. WorldCat. PhD Thesis, University of Michigian, Ann Arbor, MI →